In a recent machine learning project I was working on in semantic segmentation using transformers, I was using the typical epoch-based training loop in pytorch. After some research I decided to convert it into an iteration based training loop. I discovered that there is still confusion and debate on the differences between both approaches. In this post, I aim to explain the differences and how to apply each technique based on your own use case.
Epoch based training
Most users of pytorch would have created a training loop as follows, which is standard:
...
model.train()
model.to_device(gpu)
for epoch in range(num_epochs):
for x, y in train_dataloader:
x = x.to_device(gpu)
y = y.to_device(gpu)
y_preds = model(x)
loss = loss_criteria(y_preds, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
...The above train loop means:
-
We train the model for max
num_epochs -
At each epoch, we iterate OVER THE ENTIRE DATASET, one mini-batch at a time, to calculate the loss
-
We keep going until the all the training data has been iterated on. We then continue with the next epoch of training
The key point here is that we are iterating through the entire dataset per epoch, which is what the term itself means: Single pass over the entire dataset
This approach works well if:
-
The system we use for training has sufficient system RAM and GPU RAM to allowing loading sufficient mini-batch size of training samples per epoch.
-
Gathering metrics in a timely manner is not an issue since we can only compute the loss after an epoch completes.
From working on the semantic segmentation project, the last point was an issue for me as I was training the model in the cloud, I required regular mean IOU metrics reports for hyper parameter tuning.
Another issue I encountered was the input data to the model during training can be malformed due to unknown issues in the dataset itself or from data augmentation processes. Again, this would not be caught till much later in the training loop.
Iteration based training
A sample iteration based training loop in pytorch could be as follows:
...
model.to(device)
model.train()
while (current_iter < max_iters):
data_batch = next(iter(train_dataloader))
inputs, labels = data_batch
x = [x.to(device) for x in inputs]
y = [y.to(device) for y in labels]
y_preds = model(x)
loss = loss_criteria(y_preds, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
current_iter += 1
...The above train loop means:
-
We train the model for max_iters count
-
For each iteration, we fetch a single mini-batch of training data, in this example, via the pytorch Dataloader object. This should return an input mini-batch of size
[batch_size, channels, height, width]for an image input and[batch_size, height, width]for the labels -
We pass this mini-batch of data to the model to calculate the loss.
-
After the parameter updates, we go through another iteration with another mini-batch of data.
Note that we are not iterating over the entire dataset but rather on MINI BATCHES OF DATA.
This raises another implementation question - how do I keep fetching mini-batches of data if the number of iterations is greater than the actual dataset size? This is the subject of another post but you can use a custom iterator to catch the StopIterator exception raised and reset the iterator to the beginning of the dataset.
This approach works well if:
-
You need to have more visibility and faster feedback into the metrics per iteration.
-
You need to train the model on devices with limited system and GPU RAM by using smaller batch sizes.
-
You need to save model checkpoints at more regular intervals.
-
You need to catch training errors early on since each iteration takes shorter time to run.
-
You need to do distributed training as we can have a higher batch size and split the workload among all the workers.
The downside is we need to have cloud instances with higher amount of GPU and system RAM or multiple cloud instances in order to use larger batch sizes to accelerate training.
The training loss will vary greatly between each iteration especially if you are only able to train with mini-batch size of 1 due to hardware constraints.
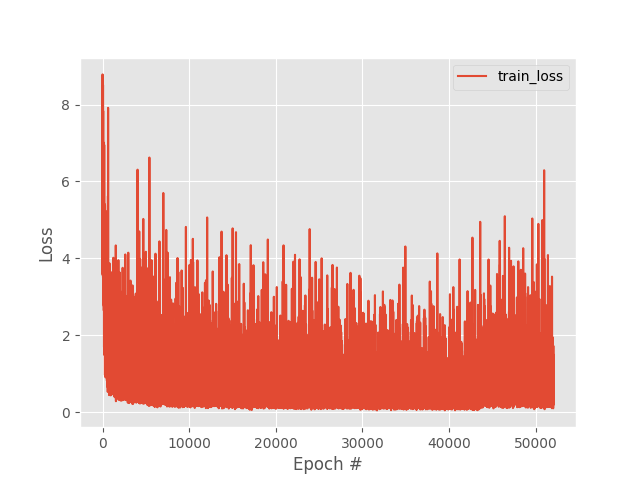
Each iteration updates the model’s parameters and if we are able to only use a mini-batch size of 1, the train loss will osciliate or vary wildy per iteration and may not be as stable as performing model updates over an entire pass of the dataset.
As of this writing, I can’t find a direct scientific explanation on which approach to take as it’s not an exact science. I would recommend trying the epoch based approach first and falling back to the iteration based approach if the former produces poor results.
I tend to use epoch based training on classifiers as it provides stable updates to the model’s parameters.
I find that using iteration based training approach for encoder-decoder based architectures such as segmentation models and GANs tend to be more stable.