A year ago, I started to research in the field of automating the parsing of receipts data using OCR. I collated a custom dataset of receipt images which are used to train a Document Understanding Transformer model. Using supervised learning, the vision model is capable of learning features from each receipt image and generating a custom JSON document representation of it.
A typical workflow to preprocess the dataset for training works like this:
- Collate receipt images from smartphone
- Upload images to a custom annotation tool such as UBIAI
- Annotate each receipt image by drawing bounding boxes on its name, line items, total spent
- Generate a JSON file of the annotation for each image
- Write custom python script to parse the JSON document representation for each image into format compatible with Donut Training data format.
Overtime, this manual process can be error prone. The annotation tool needs to be able to detect and handle text bounding boxes appropriately but in some instances, due to actual receipt image quality, it’s not possible to draw the right bounding box in the required region. The running costs of the annotation tool is also high, making it prohibitive for regular usage.
While it is ironic that the trained model is OCR-free, we still need a degree of OCR to preprocess the training images. I started to research into the use of current pretrained vision transformers model to automate some of the preprocessing steps to save costs.
The new data annotation workflow becomes:
- Detect and annotate the receipt in a given image automatically
- Generate mask of receipt from image
- Segment receipt from image
- Perform a top-down perspective transform of the receipt
- Send receipt image to 3rd party service for OCR Processing
The third step of performing a top-down perspective is important as we don’t want the OCR engine to pick up background features in the image.
1. Detecting receipt in image
For detecting the presence of a receipt in an image, I experimented with using a Grounding DINO pretrained model, which could undertake object-detection with a text prompt. The model is capable of zero-shot inference which means it doesn’t need to be pretrained on a custom dataset. The following is a code sample of using this approach:
To setup GroundingDINO:
git clone https://github.com/IDEA-Research/GroundingDINO.git
cd GroundingDINO
pip install -e .import os
from groundingdino.util.inference import load_model, load_image, predict, annotate
import supervision as sv
HOME = os.getcwd()
CONFIG = os.path.join(HOME, 'GroundingDINO/groundingdino/config/GroundingDINO_SwinT_OGC.py')
WEIGHTS_NAME = 'groundingdino_swint_ogc.pth'
WEIGHTS_PATH = os.path.join(HOME, 'weights', WEIGHTS_NAME)
model = load_model(CONFIG, WEIGHTS_PATH)
IMAGE_NAME = 'receipt.jpg'
IMAGE_PATH = os.path.join(HOME, 'data', IMAGE_NAME)
TEXT_PROMPT = 'receipt'
BOX_THRESHOLD = 0.35
TEXT_THRESHOLD = 0.25
image_source, image = load_image(IMAGE_PATH)
boxes, logits, phrases = predict(
model=model,
image=image,
caption=TEXT_PROMPT,
box_threshold=BOX_THRESHOLD,
text_threshold=TEXT_THRESHOLD
)
annotated_frame = annotate(
image_source=image_source,
boxes=boxes,
logits=logits,
phrases=phrases
)
sv.plot_image(annotated_frame)The boxes returned are the top-left and bottom-right coordinates of the bounding box. The logits refer to the confidence level of the object detection. We can use the logits as a further level to filter out predictions.
The image below is an example of the model’s prediction:

2. Generate receipt mask
Before we can segment the image, we need to convert the bounding box coordinates from step 1 to be based on the input image size:
import torch
import numpy as np
h, w, _ = image_source.shape
box = boxes[0] * torch.Tensor([w, h, w, h])
box[:2] -= box[2:] / 2
box[2:] += box[:2]
x0, y0, x1, y1 = box.int().tolist()
input_box = np.array([x0,y0,x1,y1])
input_point = None
input_label = NoneTo generate the receipt image mask, we could use the Segment Anything model. The SAM model is capable of generating masks for objects in an image given a set of bounding boxes or points. Similar to Grounding DINO, it also has strong zero-shot performance.
We pass the above bounding box coordinates to the Segment Anything model to retrive an image mask for our receipt.
To install the SAM model:
!pip install git+https://github.com/facebookresearch/segment-anything.gitTo use the model:
import torch
from segment_anything import SamPredictor, sam_model_registry
img = image_source
MODEL_TYPE = 'vit_h'
SAM_CHECKPOINT_PATH = os.path.join(os.getcwd(), 'checkpoints/sam_vit_h_4b8939.pth')
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
sam = sam_model_registry[MODEL_TYPE](checkpoint=SAM_CHECKPOINT_PATH).to(device=device)
predictor = SamPredictor(sam)
predictor.set_image(img)
masks, scores, _ = predictor.predict(
point_coords=None,
point_labels=None,
box=input_box,
multimask_output=False
)
sv.plot_image(masks[0])The model returns a mask of the detected object, based on the input box coordinates. The mask image looks as follows:

3. Segment receipt from image
To apply the mask and extract the receipt, we can apply a bitwise and to the original image via OpenCV:
import cv2
mask = np.expand_dims(masks[0], axis=0)
mask = mask.transpose(1,2,0)
mask = np.array(mask*255).astype('uint8')
mask = cv2.cvtColor(mask, cv2.COLOR_GRAY2BGR)
segmented_image = mask
segmented_image = cv2.bitwise_or(segmented_image, mask)
segmented_image = cv2.bitwise_and(segmented_image, img)
segmented_image2 = cv2.cvtColor(segmented_image, cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(segmented_image2, 127, 255, 0)
sv.plot_image(thresh)The formatted image looks like this:

4. Top-down perspective transform of image
The processed image from step 3 with the mask applied has the receipt in white against a black background. We can use the cv2.findContours function to find the outline of the receipt and apply a four-point perspective transform to create a top-down view of the image. Lastly, we apply a colour transform to give the image a scanned image look and save the image for processing later:
import cv2
contours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
img_with_contours = cv2.drawContours(img.copy(), contours, -1, (0, 255, 0), 3)
largest_contours = sorted(contours, key=cv2.contourArea, reverse=True)[:10]
receipt_contour = get_receipt_contour(largest_contours)
image_with_receipt_contour = cv2.drawContours(img.copy(), [receipt_contour], -1, (0, 255, 0), 2)
scanned = wrap_perspective(img.copy(), contour_to_rect(receipt_contour))
scanned = bw_scanner(scanned)
sv.plot_image(scanned)
cv2.imwrite('scanned.jpg', scanned)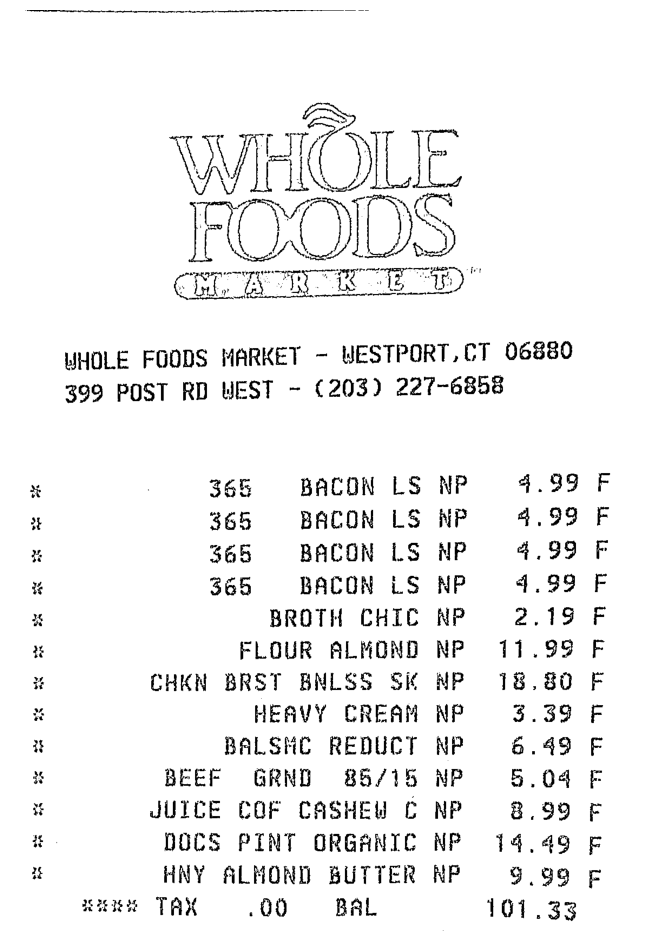
NOTE: The need to apply a top-down perspective transform is standard practice in OCR. This is to ensure that only the document object exists in the image for analysis and the content of the document object is visible.
NOTE: The above will not work if the receipt has folds/creases in its corners or sides as no contours will be found.
5. Apply OCR to obtain receipt content
Finally, we can pass the scanned image to a 3rd party OCR service to extract the textual content.
For this example, we are testing AWS Textract service as it has a bespoke function for analysis of financial documents including invoices and receipts.
We initialized a boto3 client using the Textract service and pass the local image to it using a bytes array. In production usage, the image should be saved in an S3 bucket and then retrived by Textract with the appropriate IAM permissions.
The returned output is parsed and printed onto the console:
import boto3
# https://docs.aws.amazon.com/textract/latest/dg/analyzing-document-expense.html
# Takes a field as an argument and prints out the detected labels and values
def print_labels_and_values(field):
# Only if labels are detected and returned
if "LabelDetection" in field:
print("Summary Label Detection - Confidence: {}".format(
str(field.get("LabelDetection")["Confidence"])) + ", "
+ "Summary Values: {}".format(str(field.get("LabelDetection")["Text"])))
print(field.get("LabelDetection")["Geometry"])
else:
print("Label Detection - No labels returned.")
if "ValueDetection" in field:
print("Summary Value Detection - Confidence: {}".format(
str(field.get("ValueDetection")["Confidence"])) + ", "
+ "Summary Values: {}".format(str(field.get("ValueDetection")["Text"])))
print(field.get("ValueDetection")["Geometry"])
else:
print("Value Detection - No values returned")
def process_expense_analysis(s3_connection, client, bytes_test):
# Analyze document
# process using S3 object
response = client.analyze_expense(
Document={'Bytes': bytes_test})
for expense_doc in response["ExpenseDocuments"]:
for line_item_group in expense_doc["LineItemGroups"]:
for line_items in line_item_group["LineItems"]:
for expense_fields in line_items["LineItemExpenseFields"]:
print_labels_and_values(expense_fields)
print()
print("Summary:")
for summary_field in expense_doc["SummaryFields"]:
print_labels_and_values(summary_field)
print()
if __name__ == '__main__':
session = boto3.Session(profile_name='MY_PROFILE')
client = session.client('textract')
with open('scanned.jpg', 'rb') as file:
img_test = file.read()
bytes_test = bytearray(img_test)
process_expense_analysis(None, client, bytes_test)An example output from the service:
Label Detection - No labels returned.
Summary Value Detection - Confidence: 99.99404907226562, Summary Values: 365 BACON LS NP
{'BoundingBox': {'Width': 0.41184768080711365, 'Height': 0.02726556546986103, 'Left': 0.3134370446205139, 'Top': 0.5014601349830627}, 'Polygon': [{'X': 0.3134370446205139, 'Y': 0.502947986125946}, {'X': 0.7252594828605652, 'Y': 0.5014601349830627}, {'X': 0.7252846956253052, 'Y': 0.5272407531738281}, {'X': 0.31345662474632263, 'Y': 0.5287256836891174}]}
Label Detection - No labels returned.
Summary Value Detection - Confidence: 99.99797058105469, Summary Values: 4.99
{'BoundingBox': {'Width': 0.09797967970371246, 'Height': 0.024216201156377792, 'Left': 0.8026256561279297, 'Top': 0.49942609667778015}, 'Polygon': [{'X': 0.8026256561279297, 'Y': 0.4997800290584564}, {'X': 0.9005796909332275, 'Y': 0.49942609667778015}, {'X': 0.900605320930481, 'Y': 0.5232890248298645}, {'X': 0.802649974822998, 'Y': 0.5236423015594482}]}
Label Detection - No labels returned.
Summary Value Detection - Confidence: 95.3177261352539, Summary Values: * 365 BACON LS NP 4.99 F
{'BoundingBox': {'Width': 0.9213966727256775, 'Height': 0.0309604499489069, 'Left': 0.029756179079413414, 'Top': 0.49878814816474915}, 'Polygon': [{'X': 0.029756179079413414, 'Y': 0.502117395401001}, {'X': 0.9511224031448364, 'Y': 0.49878814816474915}, {'X': 0.9511528611183167, 'Y': 0.526426374912262}, {'X': 0.02977295219898224, 'Y': 0.5297486186027527}]}
...
Summary:
Label Detection - No labels returned.
Summary Value Detection - Confidence: 99.96087646484375, Summary Values: WHOLE FOODS MARKET
{'BoundingBox': {'Width': 0.3782152831554413, 'Height': 0.029274526983499527, 'Left': 0.08396203815937042, 'Top': 0.36193326115608215}, 'Polygon': [{'X': 0.08396203815937042, 'Y': 0.36331436038017273}, {'X': 0.46215391159057617, 'Y': 0.36193326115608215}, {'X': 0.4621773064136505, 'Y': 0.3898296356201172}, {'X': 0.0839797854423523, 'Y': 0.39120781421661377}]}
Label Detection - No labels returned.
Summary Value Detection - Confidence: 99.67909240722656, Summary Values: WHOLE
FOODS
{'BoundingBox': {'Width': 0.4789944589138031, 'Height': 0.15080229938030243, 'Left': 0.2423655390739441, 'Top': 0.1238923892378807}, 'Polygon': [{'X': 0.2423655390739441, 'Y': 0.12567250430583954}, {'X': 0.7212142944335938, 'Y': 0.1238923892378807}, {'X': 0.7213599681854248, 'Y': 0.2729341983795166}, {'X': 0.24247299134731293, 'Y': 0.27469468116760254}]}
Summary Label Detection - Confidence: 92.85064697265625, Summary Values: TAX
{'BoundingBox': {'Width': 0.0692402720451355, 'Height': 0.023603398352861404, 'Left': 0.22831641137599945, 'Top': 0.9576724767684937}, 'Polygon': [{'X': 0.22831641137599945, 'Y': 0.957913875579834}, {'X': 0.2975391447544098, 'Y': 0.9576724767684937}, {'X': 0.29755666851997375, 'Y': 0.9810349941253662}, {'X': 0.22833307087421417, 'Y': 0.9812759160995483}]}
Summary Value Detection - Confidence: 92.84737396240234, Summary Values: .00
{'BoundingBox': {'Width': 0.0632663369178772, 'Height': 0.02287336438894272, 'Left': 0.3758448660373688, 'Top': 0.9591944813728333}, 'Polygon': [{'X': 0.3758448660373688, 'Y': 0.9594150185585022}, {'X': 0.4390924870967865, 'Y': 0.9591944813728333}, {'X': 0.43911120295524597, 'Y': 0.9818477630615234}, {'X': 0.37586280703544617, 'Y': 0.982067883014679}]}
...A detailed analysis of the Textract response is out-of-the-scope of this article.
In general, the service returns a structured response of the receipt content which includes metadata of the receipt such as the tax code, address and name of business. The line items store the actual items of the receipt which include the item name, quantity and cost price.
Using the response data, we can format it into Donut Training data format, replacing the custom annotation tool.
To fully implement this in AWS, we probably store the original images in an S3 bucket, which can trigger an event whenever a new image is uploaded. The newly uploaded image is then passed to a Lambda function which implements the model logic above. The processed image can be passed onto the Textract service.
Comparision to manual annotation method
The approach outlined above can be automated and scaled to hundreds of images easily using AWS Batch and Lambda. Since the pretrained models provide confidence scores, we can integrate this into a custom pipeline whereby any images that can’t be processed can be marked for manual annotation.
Comparison to using the OCR-Free model
Document Understanding Transformer model is quite capable of generating a representation of a receipt image once it has been trained properly. The approach outlined here is an attempt to automate some of the manual data preprocessing steps to speed up the training process. It’s not designed to be a replacement of the model itself. However, if your requirements are to simply extract content from a receipt, then this approach may suffice.
In production or real-world usage, I can think of situations where the approach mentioned here fails, namely, if the receipt image is creased / folded. The OCR engine will not be able to parse its contents accurately.
The Document Understanding Transformer model is invariant to such defects since it’s trained on ( image, document ) pairs. Given enough training data, the model will be able to generate a full json document representation of an image.
To summarize, I will be testing the automated approach highlighted here in an attempt to preprocess the custom receipt dataset and use it as training features for Document Understanding Transformer model.