In a recent post on the MXNet blog, it demonstrated an example of how to build a simple model inference pipeline.
Normally, a deployed model sits behind an API endpoint, accepting input requests and returning a response in the form of a prediction, be it a label for classification or real valued output for regression tasks.
In the case of a streaming data inference pipeline, we do not know in advance the frequency of the requests as data may arrive at any point in time.
A better approach to modeling the above would be to use an event driven architecture, whereby the arrival of the data stream would trigger an event and delegates the request to the model. If we deploy the model as a serverless lambda function, we could utilize the model as a service similar to how microservices work and build an inference pipeline where the prediction output could be stored or forwarded to another service for processing.
Architecture
For the purpose of this article, I re-created the architecture on AWS using the following components:
-
3 S3 buckets( one for iput; one for storing the model resources; one for storing the output )
-
Model application code deployed as a lambda service
It is now possible to run docker containers as lambda functions by using the AWS RIC library. The model code is built and packaged as a docker image which is published onto ECR. The image is specified as a source during lambda creation. The screenshot below shows this process:
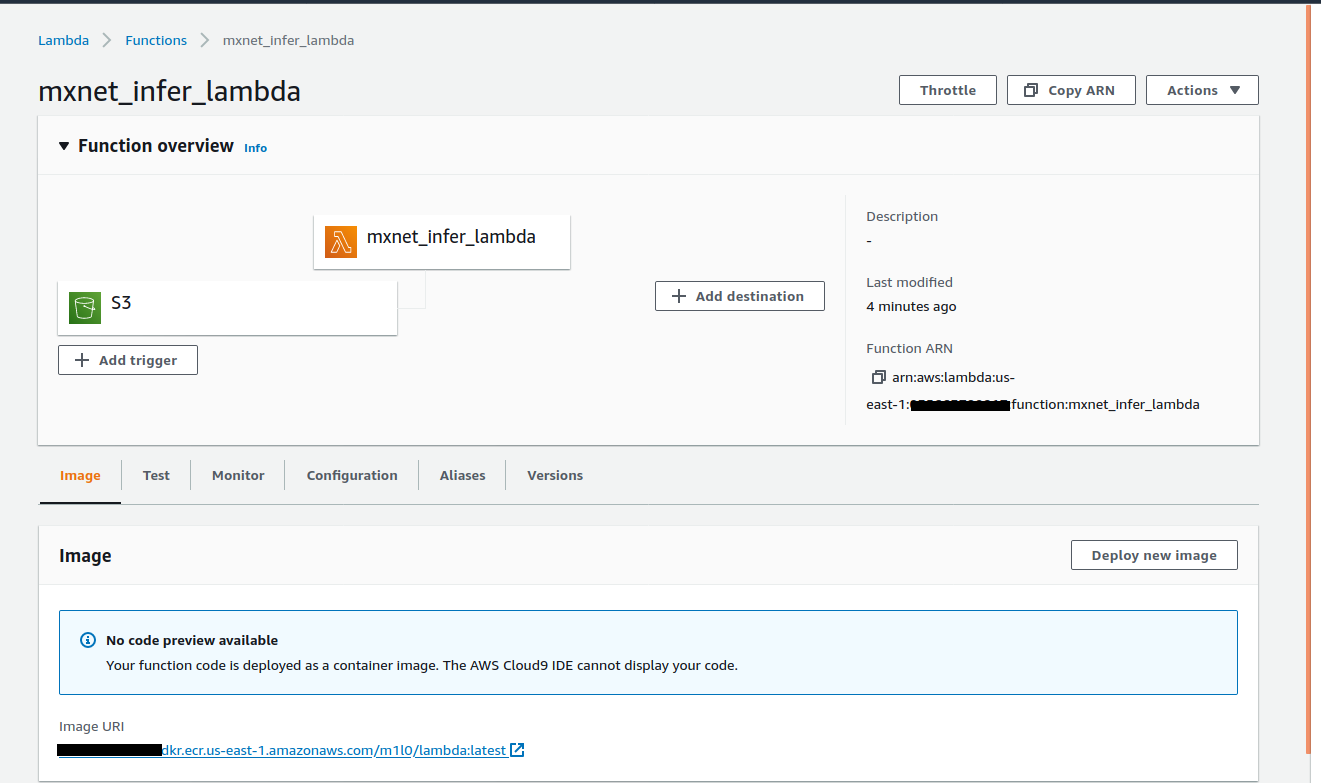
Since we are using a pretrained resnet model, we require the model’s parameters to be loaded during inference. The model’s weights and labels are stored in a resource bucket and loaded when the lambda function runs. This allows us to also enable versioning in the S3 resource bucket to load specific model versions on request.
Automation
I automated the required resources using Terraform scripts.
The scripts provisioned 3 S3 buckets and handled the lambda creation process. It also setups the required IAM roles for the right permissions to communicate between S3 and Lambda.
Inference
An event notification is setup between the input s3 bucket to the lambda function.
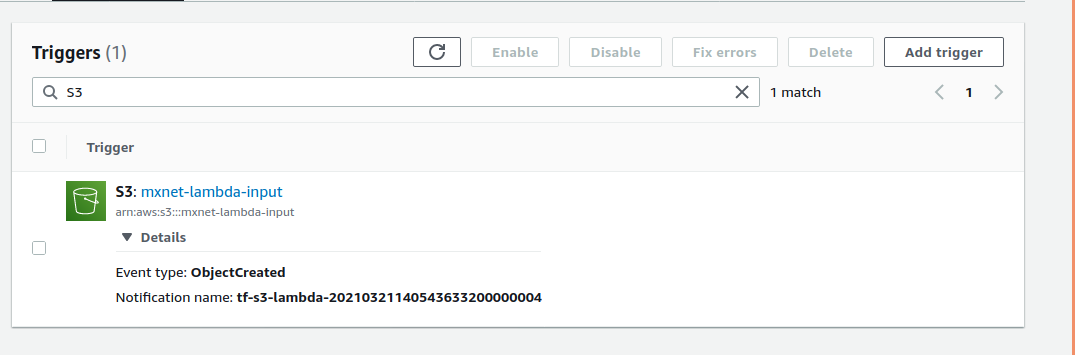
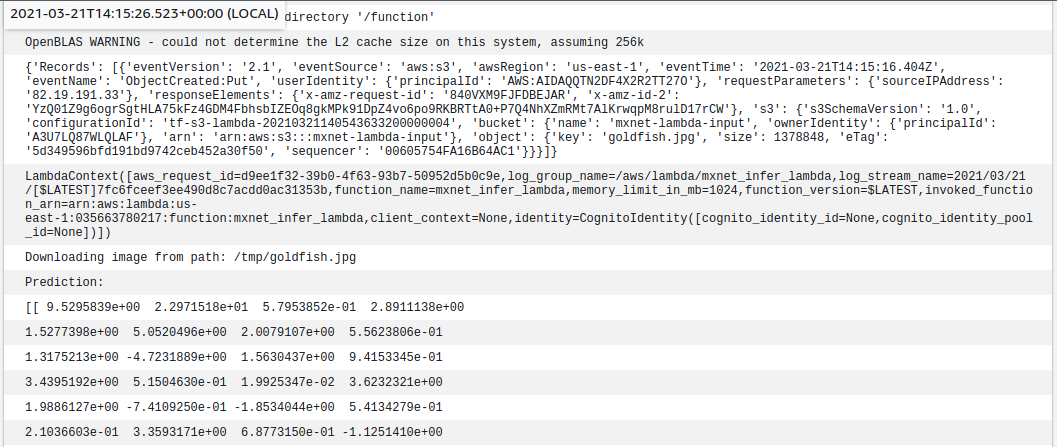
It emits object created events which are processed by the lambda function handler, which passes the object filename as an input to the pretrained ResNet model. The model makes an inference and stores the prediction into a text file in the output bucket.
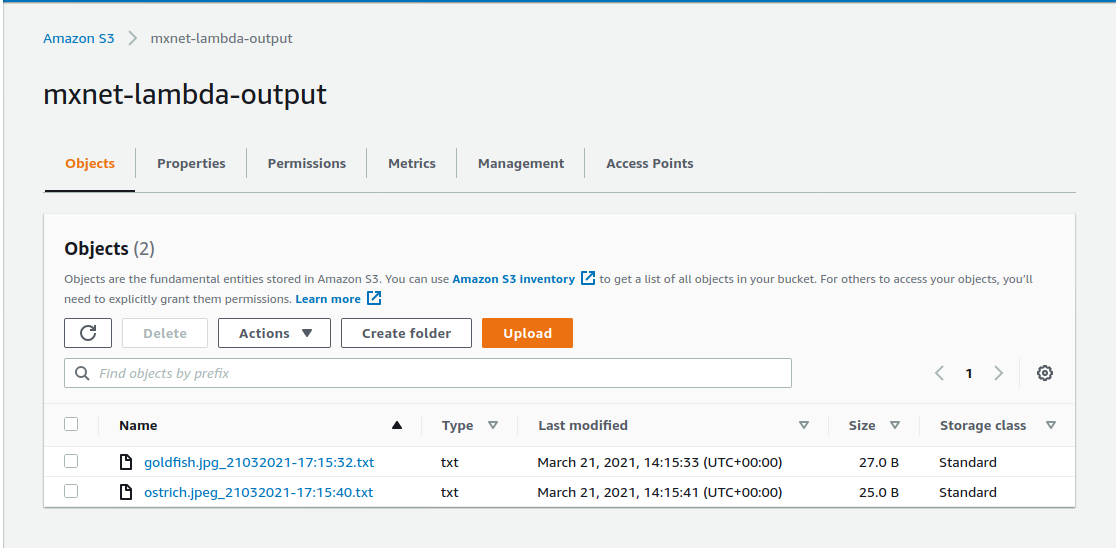
The output target can be reconfigured to be a database or another lambda function as part of a processing pipeline.
To reduce inference time, a recommended approach is to keep the lambda function in a “warm” state. This can be done by setting up a cloudwatch event that pings the lambda function every 15 seconds for instance.
Using the lambda defaults, I noticed that the model has the inclination to timeout within 3 seconds due to the loading of weights. To compensate for the possible timeouts due to loading the model, we can increase the timeout to 30 seconds and increase the memory to 1024MB for better performance. Further tests based on response times and workloads are covered in the original article.
In a further post, I aim to explore the same approach but using the latest version of MXNet built with oneDNN with Operator Fusion and Quantization built in.
The project source code can be viewed at the project github repo
Happy Hacking!