In this post, I will be discussing two commonly used types of Autoencoders: Undercomplete, and Overcomplete.
Autoencoders are a form of unsupervised neural network trained to map input to output. Its hidden layers learn an approximation of the original input, known as the latent space.
Autoencoders perform a form of feature extraction. Each layer in network learns a representation of the original features and deeper layers built upon these representations learnt by the lower layers, learning more complex representations from simpler ones. Output of autoencoder is newly learned representation of original features.
For instance, in a previous blog post on anomaly detection, the autoencoder trained on the input dataset of forest images is able to output features captured within the imagery, such as shades of green and brown hues to represent trees but was unable to fully reconstruct the input image verbatim. This is by design. If it were to return the images verbatim, it would have learnt the identity function(input) and not features inherent in the input.
An Autoencoder comprises of encoder and decoder. The encoder takes original input and outputs a different representation. The decoder takes the different representation learnt by encoder and converts it to original format.
If we represent encoder function as h = f(x) and decoder function as r = g(h), where h represents the latent space, r represents the reconstructed input, then an autoencoder tries to learn g(f(x)) for all x as input.
The loss function an Autoencoder is minimizing will be:
1
L(x, g(f(x)))
This is usually set to mean squared loss/error.
If the decoder is linear and L, loss function is the mean squared error, then the autoencoder behaves like PCA, meaning it has learnt the principal subspace of the training data
Autoencoders with non-linear encoder and decoders can learn more powerful representations of the training data but if they are given too much capacity, it will overfit and unable to learn any useful features from the training data.
Note that we are not trying to learn or copy the identity function (input); meaning if an autoencoder learns g(f(x)) = x all the time, it’s useless.
To prevent Autoencoders from copying the input data perfectly, we place/impose restrictions on its design. These restrictions prevent them from only learning the identity function and forces it to capture more salient features/properties of the data.
A common restriction would be to restrict the latent space dimension h, to be much smaller than the input feature size. This is the most common type of Autoencoder and is known as an Undercomplete Autoencoder.
For instance, if the input size is 28, the latent space could be 16.
Since Autoencoders are still neural networks, we can use pre-existing layers in tensorflow to construct them.
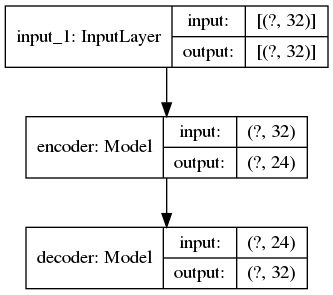
The example below shows an undercomplete autoencoder which takes in a random sample of floats with 32 dimensions, but the hidden/latent space is constrained to be of only 24 nodes.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Activation
from tensorflow.keras.layers import Input
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.models import Model
import numpy as np
latent_dim = 24
inputs = Input(shape=(32,))
x = inputs
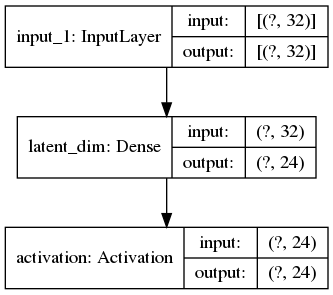
x = Dense(latent_dim)(x)
x = Activation("relu")(x)
# Encoder model
encoder = Model(inputs, x, name="encoder")
encoder.summary()
# Decoder model
latent_inputs = Input(shape=(latent_dim,))
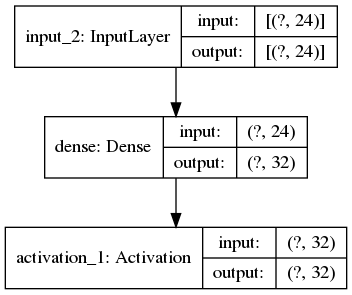
x = Dense(32)(latent_inputs)
outputs = Activation("sigmoid")(x)
decoder = Model(latent_inputs, outputs, name="decoder")
decoder.summary()
autoencoder = Model(inputs, decoder(encoder(inputs)), name="autoencoder")
autoencoder.compile(loss="mse", optimizer=SGD(lr=0.01, momentum=0.99), metrics=["accuracy"])
autoencoder.summary()
# Create fake training data of 5000 x 32 samples...
data = np.random.rand(5000, 32)
trainX, testX = train_test_split(data, test_size=0.2, random_state=42)
# Create fake training data of 5000 x 32 samples...
data = np.random.rand(5000, 32)
trainX, testX = train_test_split(data, test_size=0.2, random_state=42)
H = autoencoder.fit(trainX, trainX, epochs=epochs, batch_size=32, validation_data=(testX, testX), verbose=1)
Plots of the above model architecture is shown below:
Undercomplete Autoencoder
Encoder
Decoder
Overcomplete Autoencoders are the reverse of undercomplete. They have a larger latent space compared to the input.
For example, we could double the latent space variable in the above example to be 48 nodes, which would make it overcomplete since the hidden dimension is greater than 32.
Doing so may result in the overcomplete autoencoder just copying the training data and not learning anything useful but training could be improved/controlled using regularization techniques to prevent overfitting.
In this post, I aim to introduce what an autoencoder is and the two commonly used types: undercomplete, overcomplete. I provided an example implementation using the tensorflow Keras functional API.
In future posts, I hope to discuss more autoencoder types.
Happy Hacking.