In the paper An Image is Worth More Than 16x16 Patches, the authors proposed a novel approach to the use of patches in training vision transformers. The standard approach to training a vision transformer is to pass each image into an patch embedding layer which converts it into fixed sized sequences via convolutions.
A patch is nothing more than an additional layer in the network that applies a convolution to the image with fixed kernel and stride sizes, specified via the patch size. For example, the original ViT paper uses a patch size of 16 x 16. This means for a single ImageNet input image of 224 x 224, it would generate a sequence of length ( (224 x 224) / (16 x 16) ) 196 or 196 patches each of 16x16.
However, according to the paper, ViT still suffer from locality bias since it uses patches of fixed sizes. This means that even though the features learnt via self-attention are shared globally, the pixels within a patch are treated differently from other patches.
The paper demonstrated an approach of applying patches at the individual pixel level by applying a 1x1 convolution to generate the image sequences. This would result in longer sequence lengths. For example, a single ImageNet image of 224 x 224 would have sequence length ((224 x 224) / (1 x 1)) of 50,176. In the paper, each ImageNet image is cropped and resized to 28x28 to make the training tractable.
The paper demonstrated its findings in 3 different areas: supervised learning; self-supervised learning; and image generation. Under supervised learning, they trained a ViT model with 1x1 convolutions applied to ImageNet and CIFAR-100. To demonstrate the correlation between sequence length and patch sizes, 2 different experiements were conducted to observe the top-1 accuracy with respect to the patch size:
-
Vary the sequence length by changing both the input image size from 224x224 to 14x14 and patch size from 16x16 to 1x1.
-
Keep the input size fixed at 224x224 and vary the patch size down to 1x1
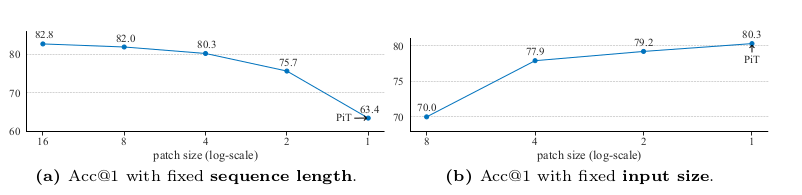
The first graph on the left shows the result of the first experiment. By reducing both the input and patch size, the top-1 accuracy fell. This indicates that input image size is an important contributor of model accuracy as it determines the amount of information a model can learn from. The second graph indicates that by keeping the input image size fixed and increasing the sequence length by reducing the patch size to pixel level, the overall top-1 accuracy increased. This shows that for a given image above a certain resolution, the patch size is not a contributor to model accuracy.
The results from both experiments show that given a sufficient image input size, we can still train it at the pixel level if the sequence length generated is sufficient for the model to learn from.
I have tried to re-create the experiment results by training a pixel transformer on the CIFAR-100 dataset by adopting a vision transformer using the configuration as highlighted by the paper, namely the PiT Tiny model. The model architecture is as follows:
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
ViT [128, 100] 196,992
├─PatchEmbedding: 1-1 [128, 1024, 192] --
│ └─Conv2d: 2-1 [128, 192, 32, 32] 768
├─Dropout: 1-2 [128, 1025, 192] --
├─Sequential: 1-3 -- --
│ └─VitBlock: 2-2 [128, 1025, 192] --
│ │ └─LayerNorm: 3-1 [128, 1025, 192] 384
│ │ └─MultiheadAttention: 3-2 [128, 1025, 192] 148,224
│ │ └─LayerNorm: 3-3 [128, 1025, 192] 384
│ │ └─VitMLP: 3-4 [128, 1025, 192] 295,872
│ └─VitBlock: 2-3 [128, 1025, 192] --
│ │ └─LayerNorm: 3-5 [128, 1025, 192] 384
│ │ └─MultiheadAttention: 3-6 [128, 1025, 192] 148,224
│ │ └─LayerNorm: 3-7 [128, 1025, 192] 384
│ │ └─VitMLP: 3-8 [128, 1025, 192] 295,872
│ └─VitBlock: 2-4 [128, 1025, 192] --
│ │ └─LayerNorm: 3-9 [128, 1025, 192] 384
│ │ └─MultiheadAttention: 3-10 [128, 1025, 192] 148,224
│ │ └─LayerNorm: 3-11 [128, 1025, 192] 384
│ │ └─VitMLP: 3-12 [128, 1025, 192] 295,872
│ └─VitBlock: 2-5 [128, 1025, 192] --
│ │ └─LayerNorm: 3-13 [128, 1025, 192] 384
│ │ └─MultiheadAttention: 3-14 [128, 1025, 192] 148,224
│ │ └─LayerNorm: 3-15 [128, 1025, 192] 384
│ │ └─VitMLP: 3-16 [128, 1025, 192] 295,872
│ └─VitBlock: 2-6 [128, 1025, 192] --
│ │ └─LayerNorm: 3-17 [128, 1025, 192] 384
│ │ └─MultiheadAttention: 3-18 [128, 1025, 192] 148,224
│ │ └─LayerNorm: 3-19 [128, 1025, 192] 384
│ │ └─VitMLP: 3-20 [128, 1025, 192] 295,872
│ └─VitBlock: 2-7 [128, 1025, 192] --
│ │ └─LayerNorm: 3-21 [128, 1025, 192] 384
│ │ └─MultiheadAttention: 3-22 [128, 1025, 192] 148,224
│ │ └─LayerNorm: 3-23 [128, 1025, 192] 384
│ │ └─VitMLP: 3-24 [128, 1025, 192] 295,872
│ └─VitBlock: 2-8 [128, 1025, 192] --
│ │ └─LayerNorm: 3-25 [128, 1025, 192] 384
│ │ └─MultiheadAttention: 3-26 [128, 1025, 192] 148,224
│ │ └─LayerNorm: 3-27 [128, 1025, 192] 384
│ │ └─VitMLP: 3-28 [128, 1025, 192] 295,872
│ └─VitBlock: 2-9 [128, 1025, 192] --
│ │ └─LayerNorm: 3-29 [128, 1025, 192] 384
│ │ └─MultiheadAttention: 3-30 [128, 1025, 192] 148,224
│ │ └─LayerNorm: 3-31 [128, 1025, 192] 384
│ │ └─VitMLP: 3-32 [128, 1025, 192] 295,872
│ └─VitBlock: 2-10 [128, 1025, 192] --
│ │ └─LayerNorm: 3-33 [128, 1025, 192] 384
│ │ └─MultiheadAttention: 3-34 [128, 1025, 192] 148,224
│ │ └─LayerNorm: 3-35 [128, 1025, 192] 384
│ │ └─VitMLP: 3-36 [128, 1025, 192] 295,872
│ └─VitBlock: 2-11 [128, 1025, 192] --
│ │ └─LayerNorm: 3-37 [128, 1025, 192] 384
│ │ └─MultiheadAttention: 3-38 [128, 1025, 192] 148,224
│ │ └─LayerNorm: 3-39 [128, 1025, 192] 384
│ │ └─VitMLP: 3-40 [128, 1025, 192] 295,872
│ └─VitBlock: 2-12 [128, 1025, 192] --
│ │ └─LayerNorm: 3-41 [128, 1025, 192] 384
│ │ └─MultiheadAttention: 3-42 [128, 1025, 192] 148,224
│ │ └─LayerNorm: 3-43 [128, 1025, 192] 384
│ │ └─VitMLP: 3-44 [128, 1025, 192] 295,872
│ └─VitBlock: 2-13 [128, 1025, 192] --
│ │ └─LayerNorm: 3-45 [128, 1025, 192] 384
│ │ └─MultiheadAttention: 3-46 [128, 1025, 192] 148,224
│ │ └─LayerNorm: 3-47 [128, 1025, 192] 384
│ │ └─VitMLP: 3-48 [128, 1025, 192] 295,872
├─Sequential: 1-4 [128, 100] --
│ └─LayerNorm: 2-14 [128, 192] 384
│ └─Linear: 2-15 [128, 100] 19,300
==========================================================================================
Total params: 5,555,812
Trainable params: 5,555,812
Non-trainable params: 0
Total mult-adds (Units.MEGABYTES): 558.82
==========================================================================================The above shows the model architecture and corresponds with the PiT tiny model of 5.6 million parameters. In order to test the model training locally, I had to wrap the model using the Fabric library. It allows you to perform mixed-precision training by transforming the float32 weights to flota16, thereby reducing the amount of GPU memory used. It also allows you to scale up the model training to FSDP across multiple GPUs with minimal changes to the training code.
Next, I adopt the following changes to the training data and the learning rate scheduler in order to fit with the paper’s configuration:
- Apply data augmentation as used in the MOCO model training. The training data has the following augemntations applied:
train_transforms = transforms.Compose([
transforms.RandomResizedCrop(32, scale=(0.2, 1.0)),
transforms.RandomGrayscale(p=0.2),
transforms.ColorJitter(0.4, 0.4, 0.4, 0.4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(*stats)
])
trainset = CIFAR100(
root="./data",
train=True,
download=True,
transform=train_transforms
)- Using a linear learning rate scheduler as warmup for initial 20 epochs followed by a cosine learning rate decay. We can utilise the LinearWarmupCosineAnnealingLR scheduler from the lightning-bolts library which allows you to specify the schedule via epochs:
lr = 0.004
weight_decay = 0.3
warmup_epochs = 20
epochs = 2400
optimizer = optim.AdamW(model.parameters(), lr=lr, betas=(0.9, 0.95), weight_decay=weight_decay)
scheduler = LinearWarmupCosineAnnealingLR(
optimizer,
warmup_epochs=warmup_epochs,
max_epochs=epochs,
warmup_start_lr=lr,
eta_min=1e-6
)The full training code can be viewed here: https://github.com/cheeyeo/ML_2024/blob/main/transformers/pit_train.py
At the time of writing, I was able to run a few training epochs on a 16GB RTX 3080 GPU. Future article will expand on updating the training code to use FSDP distributed training.
@misc{nguyen2024imageworth16x16patches,
title={An Image is Worth More Than 16x16 Patches: Exploring Transformers on Individual Pixels},
author={Duy-Kien Nguyen and Mahmoud Assran and Unnat Jain and Martin R. Oswald and Cees G. M. Snoek and Xinlei Chen},
year={2024},
eprint={2406.09415},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2406.09415},
}