We can run jobs in Flink in either Batch mode or Streaming mode. In streaming mode, we are able to save the state of the job in a specified interval. This allows for the job to resume from a given state in case of failure. These saved states are known as savepoints
A thorough discussion on the subject is beyond the scope of this post so I refer the avid reader to the Flink guide on savepoints.
An important distinction is that savepoints are different from checkpoints in the sense that the former requires user intervention while the latter is invoked by the flink cluster through for example in HA (High Availability) mode.
An important thing to note is that savepoints can only be invoked for streaming jobs; it won’t work for batch jobs.
In order to test such a functionality with the Flink Operator, we use the Kafka test guide example, which provides a streaming example using kafka pipelines.
The rest of this post assumes you have a running kind cluster with the flink operator installed. If not, please refer to the previous posts on the subject.
The following steps detail how to use such an image in a streaming job running in a kubernetes cluster locally via the flink operator:
1. Build the kafka example
We need to clone the Flink playground example and make the following changes to the Dockerfile:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
###############################################################################
# Build Operations Playground Image
###############################################################################
FROM apache/flink:1.15.2-scala_2.12-java8
WORKDIR /opt/flink/bin
# Copy s3 plugins
RUN cd ../ && \
mkdir -p plugins/s3-fs-hadoop && \
cp opt/flink-s3-fs-hadoop-1.15.2.jar plugins/s3-fs-hadoop
# Copy Click Count Job
COPY --from=builder /opt/flink-playground-clickcountjob/target/flink-playground-clickcountjob-*.jar /opt/ClickCountJob.jar
To save savepoints to remote cloud storage such as S3, we need to enable the filestorage plugins within the apache/flink image. This is done by copying the /opt/flink/opt/flink-s3-fs-hadoop-1.15.2.jar into its own plugin directory of /opt/flink/plugins/flink-s3-fs-hadoop-1.15.2.jar
Once the custom image is built we can load it into the kind cluster
2. Install kafka
Next we need to install the helm repo for the kafka cluster. The following script is adapted from Kafka test guide:
1
2
3
4
5
6
7
kubectl create ns kafka
helm repo add incubator https://charts.helm.sh/incubator
helm install my-kafka incubator/kafka --namespace kafka
helm status my-kafka -n kafka
Make the script executable and run it. Check that the namespace has the pods running.
3. Create the deployment
We need to create a generator deployment that writes data to the kafka cluster. This is adopted from the Kafka test guide:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# Example from the flink playground
# Deployment that writes data to kafka cluster
apiVersion: apps/v1
kind: Deployment
metadata:
name: kafka-click-generator
spec:
replicas: 1
selector:
matchLabels:
app: kafka-click-generator
template:
metadata:
labels:
app: kafka-click-generator
spec:
containers:
- name: kafka-click-generator
image: m1l0/flink-ops-playground:1.15.2-scala_2.12
command: ["java"]
args:
- "-classpath"
- "/opt/ClickCountJob.jar:/opt/flink/lib/*"
- "org.apache.flink.playgrounds.ops.clickcount.ClickEventGenerator"
- "--bootstrap.servers"
- "my-kafka.kafka.svc.cluster.local:9092"
- "--topic"
- "input"
Note that we are using our own custom image built in step 1.
Create the deployment and check that the pods are running.
4. Create the consumer
The consumer of the data stream is a flink operator job that runs the ClickCount.jar application that consumes data from the kafka stream.
The job is deployed as a standalone application cluster via the flink operator.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
apiVersion: flinkoperator.k8s.io/v1beta1
kind: FlinkCluster
metadata:
name: clickcount
spec:
flinkVersion: "1.15.2"
image:
name: m1l0/flink-ops-playground:1.15.2-scala_2.12
pullPolicy: IfNotPresent
jobManager:
ports:
ui: 8081
resources:
limits:
memory: "2Gi"
cpu: "200m"
taskManager:
replicas: 2
resources:
limits:
memory: "2Gi"
cpu: "200m"
envVars:
- name: ENABLE_BUILT_IN_PLUGINS
value: flink-s3-fs-hadoop-1.15.2.jar;
- name: AWS_ACCESS_KEY_ID
valueFrom:
secretKeyRef:
name: flink-aws-secret
key: access_key_id
- name: AWS_SECRET_ACCESS_KEY
valueFrom:
secretKeyRef:
name: flink-aws-secret
key: secret_access_key
job:
jarFile: /opt/ClickCountJob.jar
className: org.apache.flink.playgrounds.ops.clickcount.ClickEventCount
args:
[
"--bootstrap.servers",
"my-kafka.kafka.svc.cluster.local:9092",
"--checkpointing",
"--event-time",
]
parallelism: 1
savepointsDir: "s3a://flinkexps/savepoints"
autoSavepointSeconds: 10
flinkProperties:
taskmanager.numberOfTaskSlots: "1"
There are several important things to note here.
The ENABLE_BUILT_IN_PLUGINS is required to allow the plugins to be copied over to the client else the job will fail with plugins not found error.
The AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY_ID are fetched from a kubernetes secret and mounted as env vars within the job container.
Within the job spec we need to declare the following 2 properties to allow for automatic savepoint creation via the flink operator.
The savePointsDir is the target location of our savepoints. Note that the file system prefix is s3a as we are using the hadoop filesystem integration and it only works with that prefix.
We also need to declare autoSavepointSeconds which is a non-negative integer which specifies how often to create a savepoint. In this example we set it to a lower/frequent interval of 10secs to test if it works.
Apply the above configuration and check the status of the job submitted via:
1
kubectl describe flinkcluster clickcount
If all goes well, after 10 seconds, you should see a stream of savepoints being created
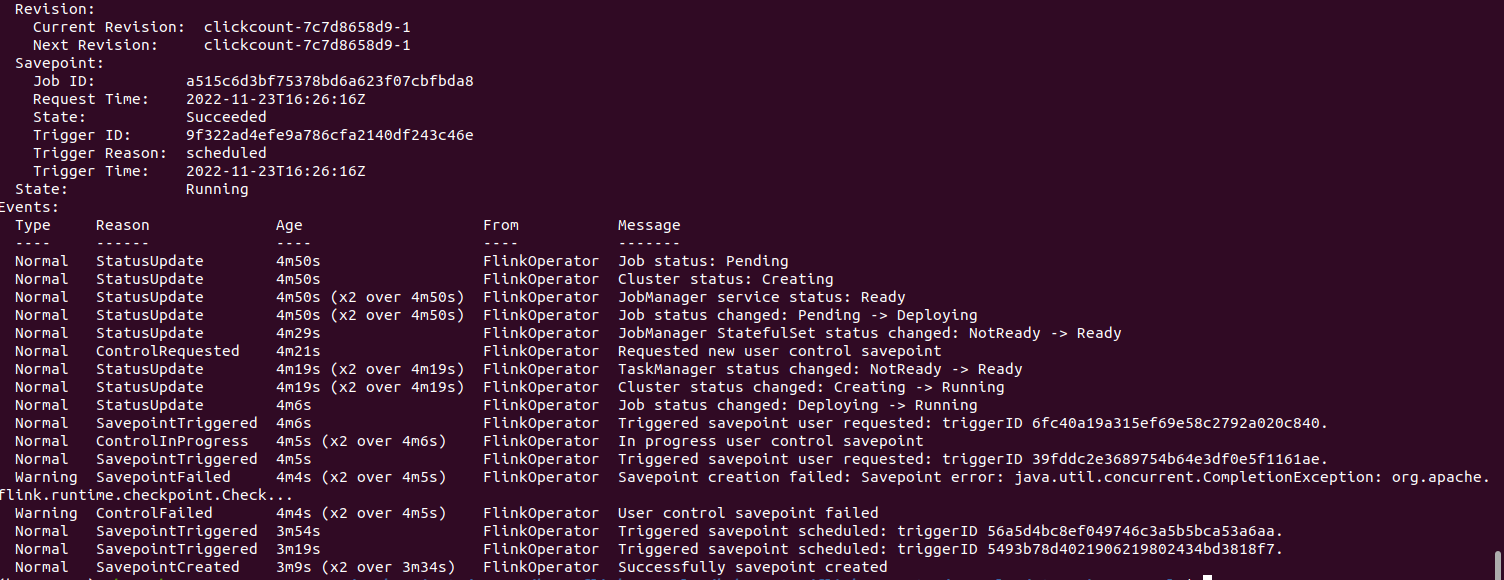
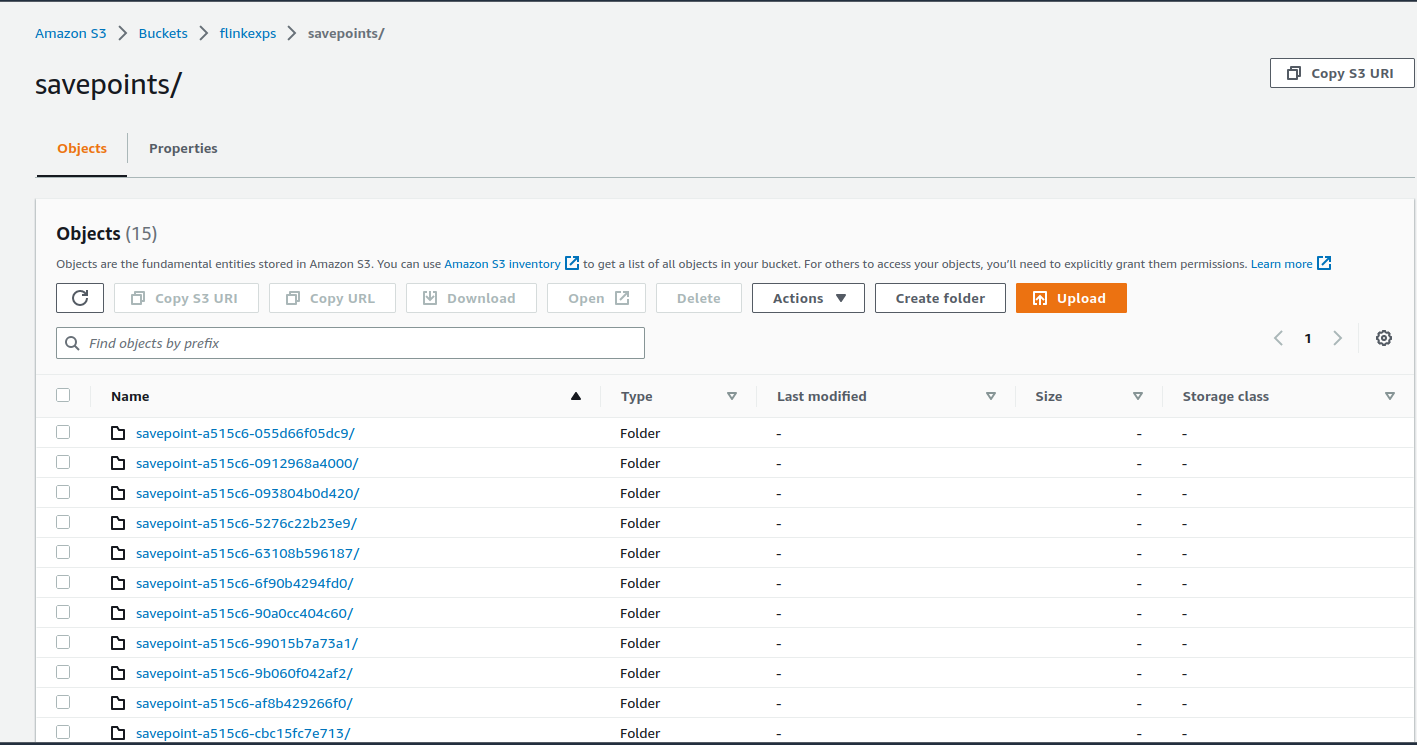
5. Triggering savepoints
You can also trigger the manual creation of savepoints as highlighted in the Flink operator savepoints guide. Of all the approaches listed, the easiest one I found to work for me was to annotate the cluster manually.
For example, given the flinkcluster resource above, I can run:
1
kubectl annotate flinkclusters clickcount flinkclusters.flinkoperator.k8s.io/user-control=savepoint
You should see the message User control savepoint triggered event message and the savepoint shown under the job specs.
Saving artifacts
To save artifacts to S3 from batch jobs, we need to do the same as above:
- Create a custom image where we copy over the hadoop s3 plugins
- Create and mount the env vars
- Specify the target s3 bucket with s3a prefix
Below is an example of a batch job submitted to the flink operator:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
apiVersion: flinkoperator.k8s.io/v1beta1
kind: FlinkCluster
metadata:
name: pyflink-wordcount
namespace: default
spec:
flinkVersion: "1.15.2"
image:
name: m1l0/pyflink:1.15.2-scala_2.12
pullPolicy: IfNotPresent
taskManager:
replicas: 1
# Below is needed to access attached volumes as flink user
securityContext:
runAsUser: 9999
runAsGroup: 9999
fsGroup: 9999
envVars:
- name: ENABLE_BUILT_IN_PLUGINS
value: flink-s3-fs-hadoop-1.15.2.jar;
- name: AWS_ACCESS_KEY_ID
valueFrom:
secretKeyRef:
name: flink-aws-secret
key: access_key_id
- name: AWS_SECRET_ACCESS_KEY
valueFrom:
secretKeyRef:
name: flink-aws-secret
key: secret_access_key
job:
pyFile: "examples/python/datastream/word_count.py"
args: ["--output", "s3a://flinkexps/artifacts/pyflink/"]
restartPolicy: Never
flinkProperties:
s3.path.style.access: "true"
The above runs an example pyflink job provided in the Flink docker image which we customized by copying over the hadoop plugins. Note that the same env vars as specified for streaming jobs must be present for it to work in batch mode.
Summary
This post attempts to explain how to create and store savepoints in remote cloud storage either through running a streaming job or as the artifacts of a batch job.
In the next posts, I will attempt to cover checkpoints and the high availability mode in a flink cluster.
H4ppy H4ck1n6 !!!