In the previous post, I described a process of using docker compose to setup a suite of services to develop and run BEAM jobs on a flink cluster. To mimic production scenarios, we can use a container orchestration platform such as kubernetes to manage these services.
In this post, I attempt to highlight the process of setting up a local kind cluster to deploy and manage a flink session cluster using the Flink Kubernetes operator.
Setting up the kind cluster
To setup a flink cluster in kind we need to have kind installed locally.
To create a kind cluster:
1
kind create cluster --name flinkcluster --config kind_config.yaml
The config file I used was documented on the website and as follows:
It exposes the host system ports 80 and 443 to allow the ingress controller to map those ports in order to access the UI which we will describe later.
It also maps a local directory /tmp/artifacts into the node as type of host path. This can be referenced in pods with the path of /artifacts. The local directory must be created with the owner and group of 9999 before the flink task manager can read/write to it.
1
2
3
mkdir -p /tmp/artifacts
sudo chown -R 9999:9999 /tmp/artifacts
Check that the cluster is running and set the kubectl context:
1
2
3
kind get clusters
kubectl cluster-info --context kind-flinkcluster
2. Setup and load docker images
Kind cluster doesn’t have access to the local docker images on the host system so they must be preloaded into the cluster. The following are some of the images we preload:
1
2
3
4
5
6
7
kind load docker-image apache/beam_python3.8_sdk:2.41.0 --name flinkcluster
kind load docker-image apache/flink:1.15.2 --name flinkcluster
kind load docker-image apache/beam_flink1.15_job_server:2.41.0 --name flinkcluster
kind load docker-image m1l0/pyflink:1.15.2-scala_2.12 --name flinkcluster
The first 3 images will be used by the flink session cluster and job server. The last image is a custom image which contains both python and pyflink installed as the default flink image is designed to run in Java.
The Dockerfile I used is as follows and adapted from Flink Kubernetes operator:
The dockerfile uses apache/flink:1.15.2-scala_2.12 as a base / builder image, installs some flink connectors such as mysql and hadoop and installs and builds python and pyflink.
3. Setup Flink operator
To install the Flink operator, we need to install its dependencies:
- certmanager
- ingress nginx controller
To install certmanager
1
kubectl apply -f https://github.com/jetstack/cert-manager/releases/download/v1.8.1/cert-manager.yaml
Next we install ingress nginx controller
1
kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/main/deploy/static/provider/kind/deploy.yaml
The ingress controller will create a ingress object for the flink dashboard.
Next we install the flink operator:
1
kubectl apply -f https://github.com/spotify/flink-on-k8s-operator/releases/download/v0.4.2-beta.4/flink-operator.yaml
Next we verify that the flink operator components are installed correctly:
1
2
3
4
5
6
7
8
9
kubectl get crds | grep flinkclusters.flinkoperator.k8s.io
kubectl describe crds/flinkclusters.flinkoperator.k8s.io
kubectl get deployments -n flink-operator-system
kubectl get pods -n flink-operator-system
kubectl logs -n flink-operator-system -l app=flink-operator --all-containers
4. Create flink resources
We need to setup the following resources to create the cluster:
4.a Volumes
We create two sets of volumes and persistent volume claims.
We create a persistent volume and a persistent volume claim as the taskmanager and job server need to share a common staging space to access the uploaded artifacts, similar to the docker setup. This creates a volume on the node at path /mnt/data, mounted into /tmp/beam-staging in the pod
The second set of volume and claim creates a volume to store the job artifacts. When applied, if the output path for a job is specified as /artifacts, the final output can also be accessed locally on the host.
Applying the above:
1
2
3
kubectl apply -f flink_pvc.yaml
kubectl apply -f flink_pvc_artifacts.yaml
4.b Flink session cluster and job server
The flink session cluster is based on a CRD FlinkCluster defined by the flink operator. Note that in this example we are defining a session cluster hence there is no job spec defined. If job spec is defined, the operator automatically provisions an application cluster which runs the job once and exits.
Another important note is that we are using the custom image we built earlier which includes python and pyflink. This is essential as pyflink jobs will not be able to run and fails with python not found
The python BEAM jobs are not affected by this as we are using the python beam sdk to submit the job which we will show later.
The flink_ui_svc.yaml creates an Ingress resource in order to allow external traffic to the UI. Since we have exposed ports 80 in our kind cluster, we can access the UI with localhost/default/ui in the browser.
Applying the above:
1
2
3
4
5
kubectl apply -f flink_session_cluster.yaml
kubectl apply -f flink_job_server.yaml
kubectl apply -f flink_ui_svc.yaml
Check that the resources are deployed correctly and running:
1
kubectl get pods -lapp=flink
The pods should show status of running and the UI is accessible at http://localhost/default/ui/

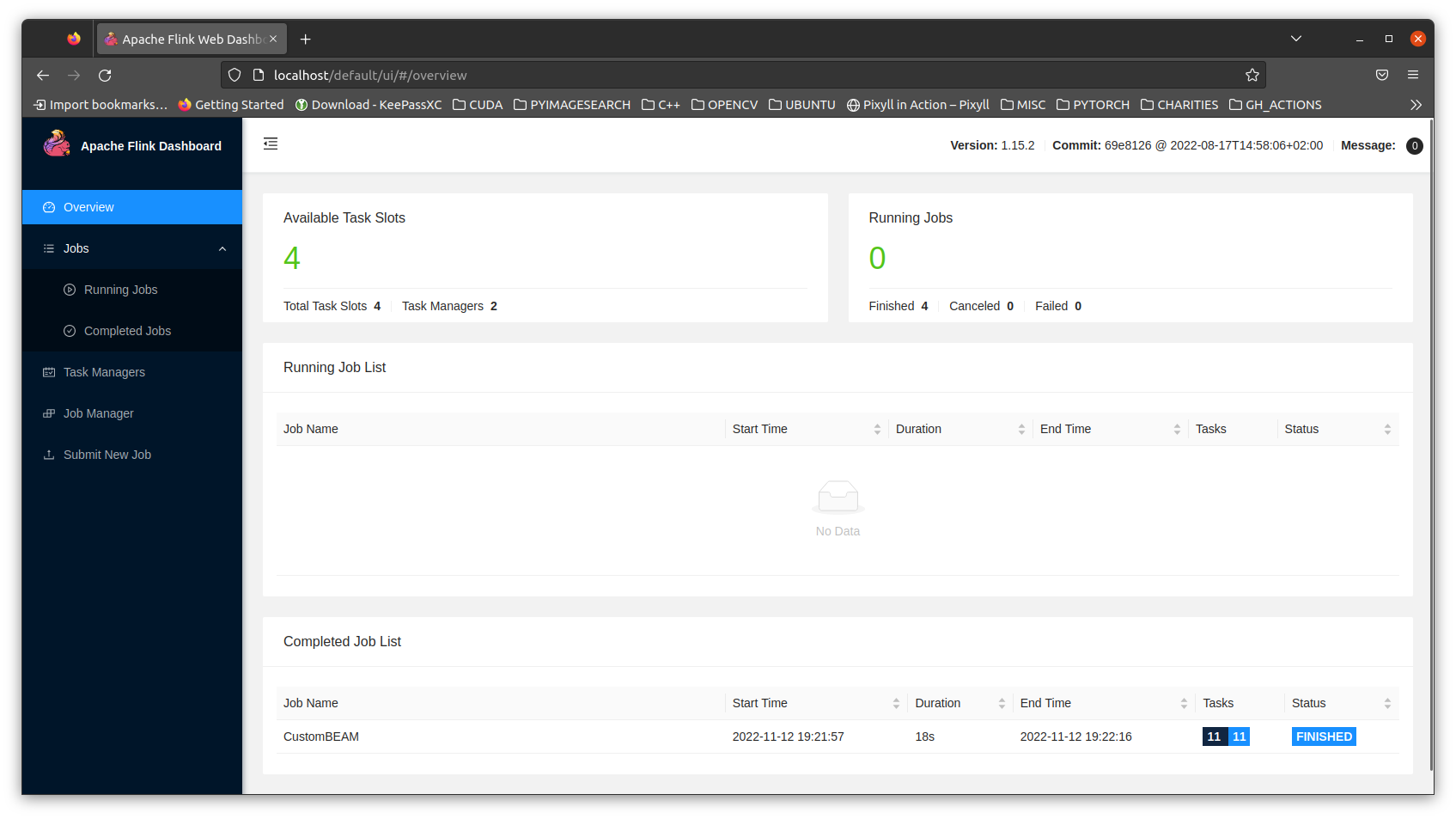
We can test the current setup using the following example job:
This defines an python beam job using the python sdk. Once the job is created, it gets submitted to the beam-job-server service running on port 8099 which translates it into Flink compatible job. The environment_type and environment_config refers to the python BEAM sdk which Flink uses when it executes python code.
The screenshot below shows the job completion in the UI:
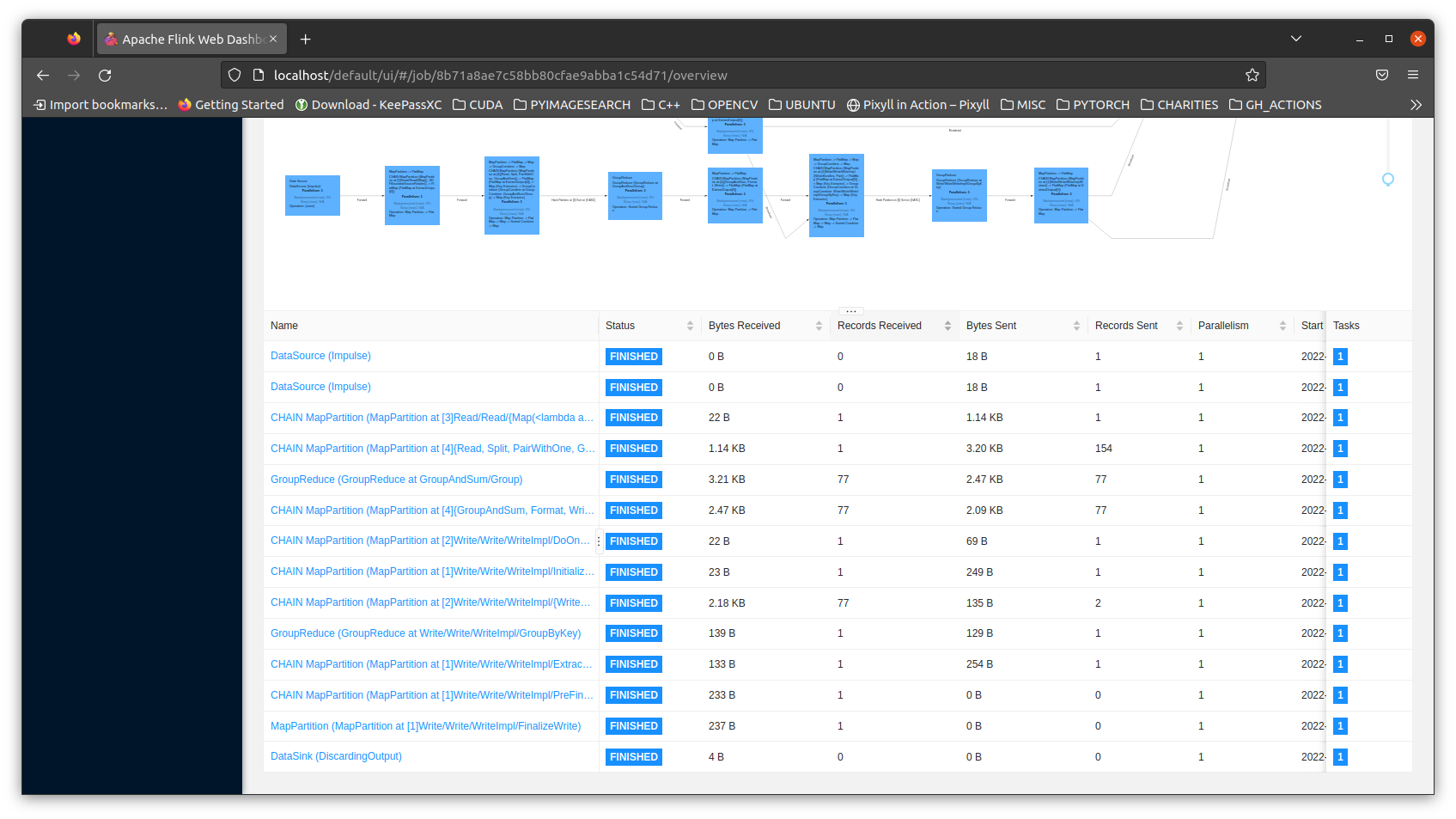
Check in the UI and pod logs that the job has completed successfully.
1
2
3
4
5
6
7
8
9
10
kubectl logs beam-wordcount-py-jpkqx
INFO:root:Default Python SDK image for environment is apache/beam_python3.8_sdk:2.41.0
INFO:apache_beam.runners.portability.fn_api_runner.translations:==================== <function pack_combiners at 0x7fe9064305e0> ====================
INFO:apache_beam.runners.portability.fn_api_runner.translations:==================== <function lift_combiners at 0x7fe906430670> ====================
INFO:apache_beam.runners.portability.fn_api_runner.translations:==================== <function sort_stages at 0x7fe906430dc0> ====================
INFO:apache_beam.runners.portability.portable_runner:Job state changed to STOPPED
INFO:apache_beam.runners.portability.portable_runner:Job state changed to STARTING
INFO:apache_beam.runners.portability.portable_runner:Job state changed to RUNNING
INFO:apache_beam.runners.portability.portable_runner:Job state changed to DONE
The job can run on any of the taskmanagers which is referenced in the job UI. The outputs will be stored in the beam-worker-pool sidecar container which can be accessed like so:
1
kubectl exec -it beam-flink-cluster-taskmanager-0 -c beam-worker-pool -- bash
If the /artifacts path is mounted into the cluster, the output can be accessed locally.
5. Running custom BEAM jobs
To run your own custom BEAM job we need to:
-
Create a custom docker image using the apache python SDK image with the custom python files / modules loaded.
-
Create a kubernetes job spec with the above custom image.
-
Submit the job into the kubernetes cluster.
A dockerfile could look like this:
1
2
3
4
5
6
# Example dockerfile to build a custom image to run beam job
FROM apache/beam_python3.8_sdk:2.41.0 as builder
WORKDIR /opt/flink
COPY beam_example.py .
Here we use the apache/beam_python3.8_sdk:2.41.0 as the builder image and add our python beam code into the image.
The sdk image has already been preloaded into the kind cluster earlier. Next we need to load this custom job image into the cluster:
1
kind load docker-image beam:custom --name flinkcluster
A job manifest flink_beam_example.yaml can look like this:
To submit the job:
1
kubectl apply -f flink_beam_example.yaml
The job should appear in the UI:
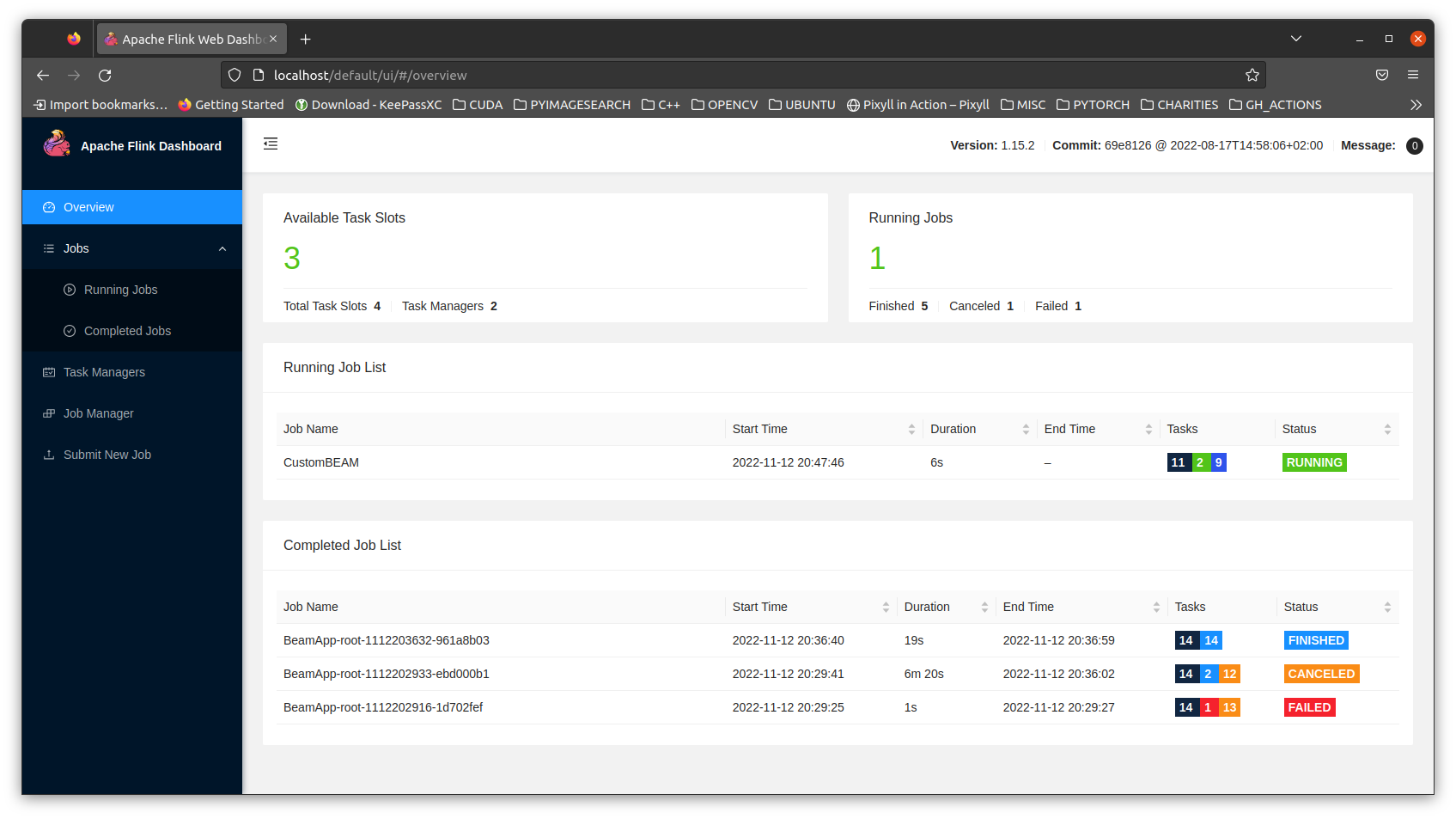
6. Running custom PyFlink job
Earlier we detailed how we use the apache/flink:1.15.2 image as a base image to build a custom image containing python, pyflink and other connectors. This is the same image we use to create and run our custom PyFlink jobs.
This follows a similar process:
-
Create a custom docker image using the custom apache flink image with the custom python files / modules loaded
-
Create a kubernetes job spec with the above custom image
-
Submit the job into the kubernetes cluster
An example dockerfile could be:
1
2
3
4
5
6
7
# Example dockerfile to build a custom image to run pyflink job
# NOTE: The pyflink image must have python else it fails with python not found and job fails?
FROM m1l0/pyflink:1.15.2-scala_2.12 as builder
WORKDIR /opt/flink
COPY pyflink_example.py .
Create a job manifest as follows:
Note that the beam-flink-cluster-jobmanager is created as a service earlier. Here we run the custom pyflink file by using the /opt/flink/bin/flink CLI tool, passing in the –python argument which will cause the job to be parsed and submitted as a python code.
Submit the job and monitor the UI for job status.
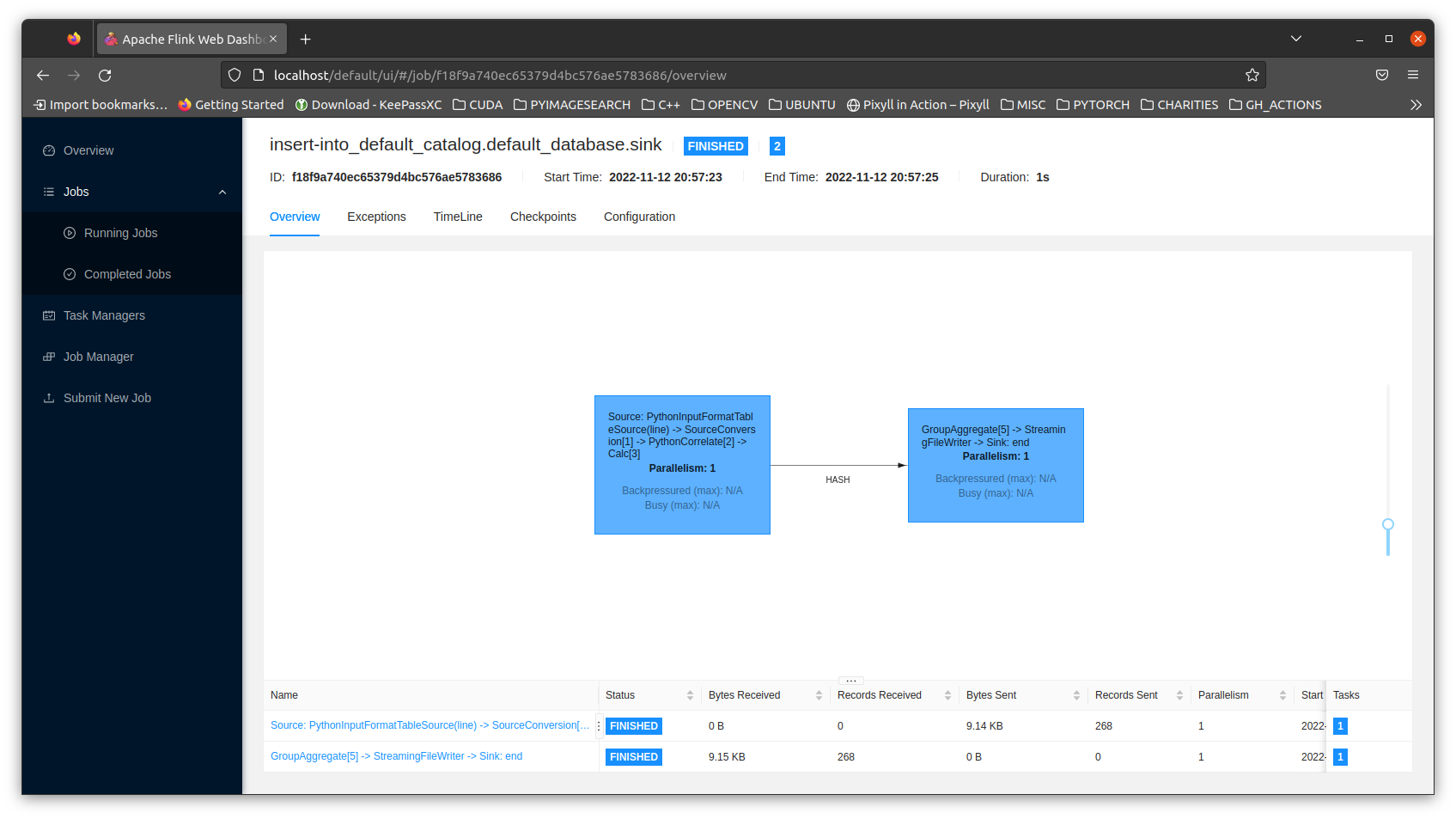
Access the job artifacts by execing into the taskmanager pod and accessing the taskmanager container since the job is run directly on the flink cluster this time.
7. Running custom PyFlink job in Application Mode
The operator supports running jobs in either session or application mode. The steps before detailed job submission via the session mode to a standalone flink cluster.
When run in application mode, the operator creates an individual flink cluster with job and task managers to execute the job.
An example PyFlink application job:

The operator creates a standalone flink cluster comprising of a jobmanager, taskmanager to run the job. It also creates 2 jobs: the actual job defined in the spec, and a submitter job which uses the flink CLI tool to submit the job and reports on it status and logs.
To view the status and logs of the job:
1
kubectl describe pod pyflink-wordcount-cluster-job-submitter-tn5zz
Sample output of the logs:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
...
State: Terminated
Reason: Completed
Message: jobID: 85cda7250d75e94dee8586f90f757871
message: |
Successfully submitted!
/opt/flink/bin/flink run --jobmanager pyflink-wordcount-cluster-jobmanager:8081 --parallelism 1 --detached --python examples/python/datastream/word_count.py --output /artifacts/application
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.apache.hadoop.security.authentication.util.KerberosUtil (file:/opt/flink/lib/flink-shaded-hadoop-2-uber-2.8.3-7.0.jar) to method sun.security.krb5.Config.getInstance()
WARNING: Please consider reporting this to the maintainers of org.apache.hadoop.security.authentication.util.KerberosUtil
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
Job has been submitted with JobID 85cda7250d75e94dee8586f90f757871
Executing word_count example with default input data set.
Use --input to specify file input.
...
Sample of the generated output:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
(a,5)
(Be,1)
(Is,1)
(No,2)
(Or,1)
(To,4)
(be,1)
(by,2)
(he,1)
(in,3)
(is,2)
(my,1)
(of,14)
(or,1)
(so,1)
(to,7)
(us,3)
(we,4)
(And,5)
(But,1)
...
Cleanup
One can delete the entire kind cluster using the following to remove all resources:
1
kind delete cluster --name flinkcluster
Summary
The post attempts to explain how to run a Flink cluster locally in a kind cluster using the Flink operator.
Using the operator has simplified the process of managing and applying various disparate kubernetes config files which is error prone. Defining a flink cluster and job as custom resource definition also simplifies resource management and further interoperability with the kubernetes API.
The downside of this approach is it involves more automation in order to package and deploy custom jobs locally into the cluster. I see this particular setup as more of a pre-deployment or test environment of a BEAM/Flink job before running it in an actual cluster remotely.
These are the remaining areas which remains to be researched on:
- Install operator using helm chart
- Custom application to create a job resource dynamically
- Use of savepoints to save and restore running jobs
- Use of connectors such as S3 to save artifacts and savepoints remotely.
H4ppy H4ck1n6 !!!