In an ongoing project to perform OCR on a custom dataset of receipt images, I had to manually annotate the dataset using a commercial labelling toolkit. The issue is as the amount of data increased, the manual process became more error prone and time consuming. This had an effect on the overall training accuracy of the resulting model.
I started to investigate ways to build a custom data pipeline and came across Airflow. It’s a platform that allows you to define custom workflows and pipelines in pure python. It is also supported on AWS as Managed Workflows for Apache Airflow.
While an explanation of Airflow is outside the scope of this article, I encourage checking out the main website and documentation to get started. The rest of the article explains how I built and structured the data pipelines. All the examples presented here are run locally via Docker compose using the compose template provided by Airflow.
On dataset preparation
The training dataset comprises of a personal collection of receipts collated over time. Each receipt image had to be annotated by drawing bounding boxes around each item of interest which included the premises name; each line item description, name and price; the subtotal and total amounts. The annotations for each image is converted into JSON which is parsed by a custom script to prepare it in a format suitable for model training.
To automate the process above, I created the following workflow for each image:
- Remove any personal data via EXIF
- Rescale the image to a smaller size while preserving aspect ratio
- Use a large vision model such as DINO to calculate the bounding box of a receipt in the input image
- Use a second large vision model such as SAM to segment the receipt from the previous bounding box coordinates
- Apply further computer vision processing to segmented image to create a scanned document effect i.e. perspective transform, colourization
- Save processed image to a storage location for further processing
In terms of AWS infrastructure, I created the following:
-
2 S3 Buckets, one to host the original input images; the second to host the processed images.
-
An SQS queue, which is used by the host S3 bucket to send its event notifications to whenever a new image is uploaded to it.
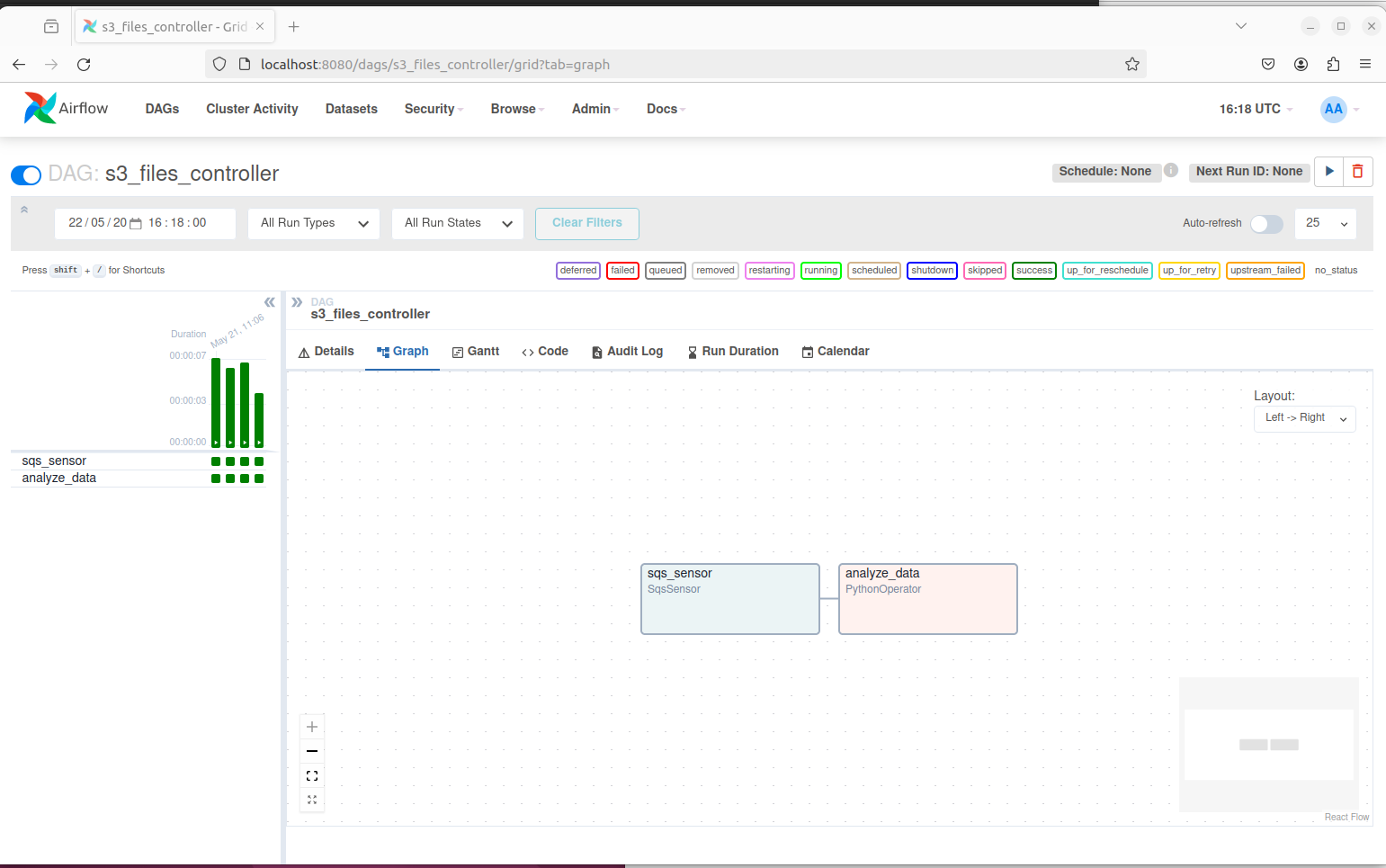
Within Airflow, I created two separate DAGs ( Directed Acyclic Graphs ) to host the workflow tasks. The first DAG has an SQS sensor waiting on the SQS queue for new images being uploaded.
From the script above, we created a dag with id of s3_files_controller. It uses an SqsSensor which polls the given SQS queue for new messages. Once a message is received, it triggers the PythonOperator analyze_data which invokes a python function to process each message. Note that on line 21, we use the airflow client object to make an API call to trigger the second DAG which performs the actual image processing.
The image of the DAG from the console UI:
The second DAG is as follows:
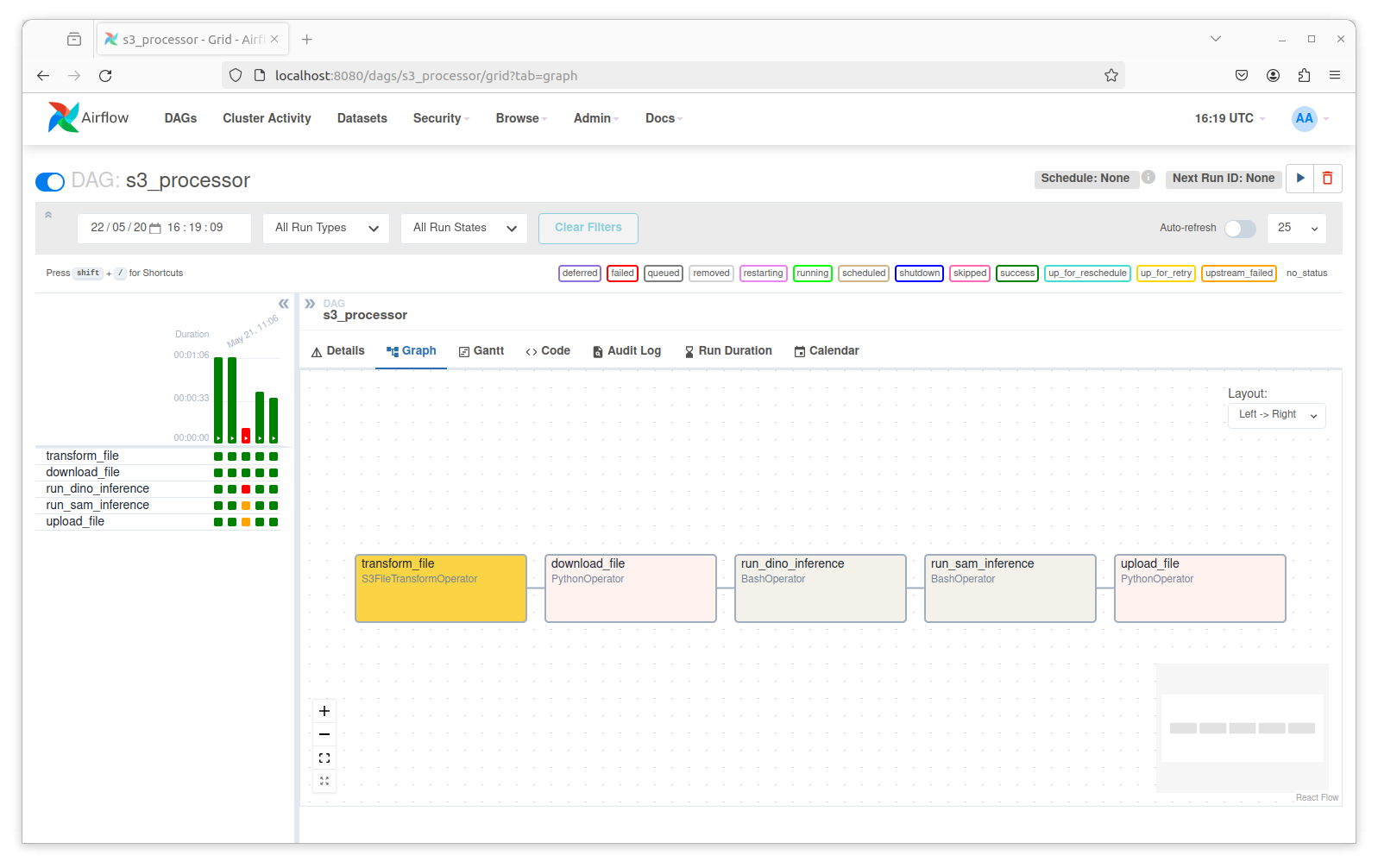
We created a DAG with id of s3_processor. The first step in the workflow uses the S3FileTransformOperator which receives as inputs the parameters from the API client call from the first DAG. This is in the line dag_run.conf.get('source_filename') which uses Jinja style syntax to pass variables into operators. The operator invokes a custom script at '/opt/airflow/dags/image_processor.py' which performs preprocessing on the image data that includes removing EXIF data and resizing the image. The resultant image is saved into the target S3 bucket defined in dag_run.conf.get('dest_filename')
The second task downloads the S3 file from the previous task for processing.
The third task calls a custom python script using the BashOperator to run inference using DINO model from HuggingFace to extract the bounding box coordinates of the receipt in the image. If none exists, the script raises an exception and the workflow terminates. The inference script returns the bounding box coordinates as the last printed line in JSON format of the form:
"{'coords': '[[0, 0, 300, 200], [0, 0, 300, 200]]'}The fourth task calls a custom python script using the BashOperator to run inference using MobileSAM from ultralytics. This is a lightweight model with a million parameters and is suitable for inference. The script takes in two parameters as inputs: the image to be processed; the return coordinates from the previous task. The script uses the bounding-box coordinates to segment the object from the image. It performs the following image operations:
- Convert segmented image to grayscale
- Performs thresholding
- Find the image contours
- Retrieve the largest image contour
- Performs perspective transform on contours
- Convert image to B&W scanned format
The final task takes the saved image from above and saves it to the destination location.
The image of the DAG from the console UI:
The converted image is then ready to be passed to a service such as AWS Textract to perform OCR to extract individual line items from the processed images to the desired model training format.
The following shows the images before and after by the workflow:

Improvements
While the above is a better approach than manual labeling, further improvements can be made.
The model inference scripts can be refactored into services which can reside in its own Docker images with its own dependencies. We can utilize frameworks such as FastAPI for async requests. The workflow would be simplified to an API call rather than having multiple steps.
The opencv operations to calculate the thresholds for the segmented object image needs to be tested and refined for images with receipts with creased or folded edges. It also needs further denoising applied to it in some cases to generate a higher-resolution image for OCR processing.
The airflow runtime could also be tested with AWS Managed Workflows Local Runner before deployment to AWS.
Summary
To conclude, this article aims to introduce an approach to using Airflow to process unstructured datasets.